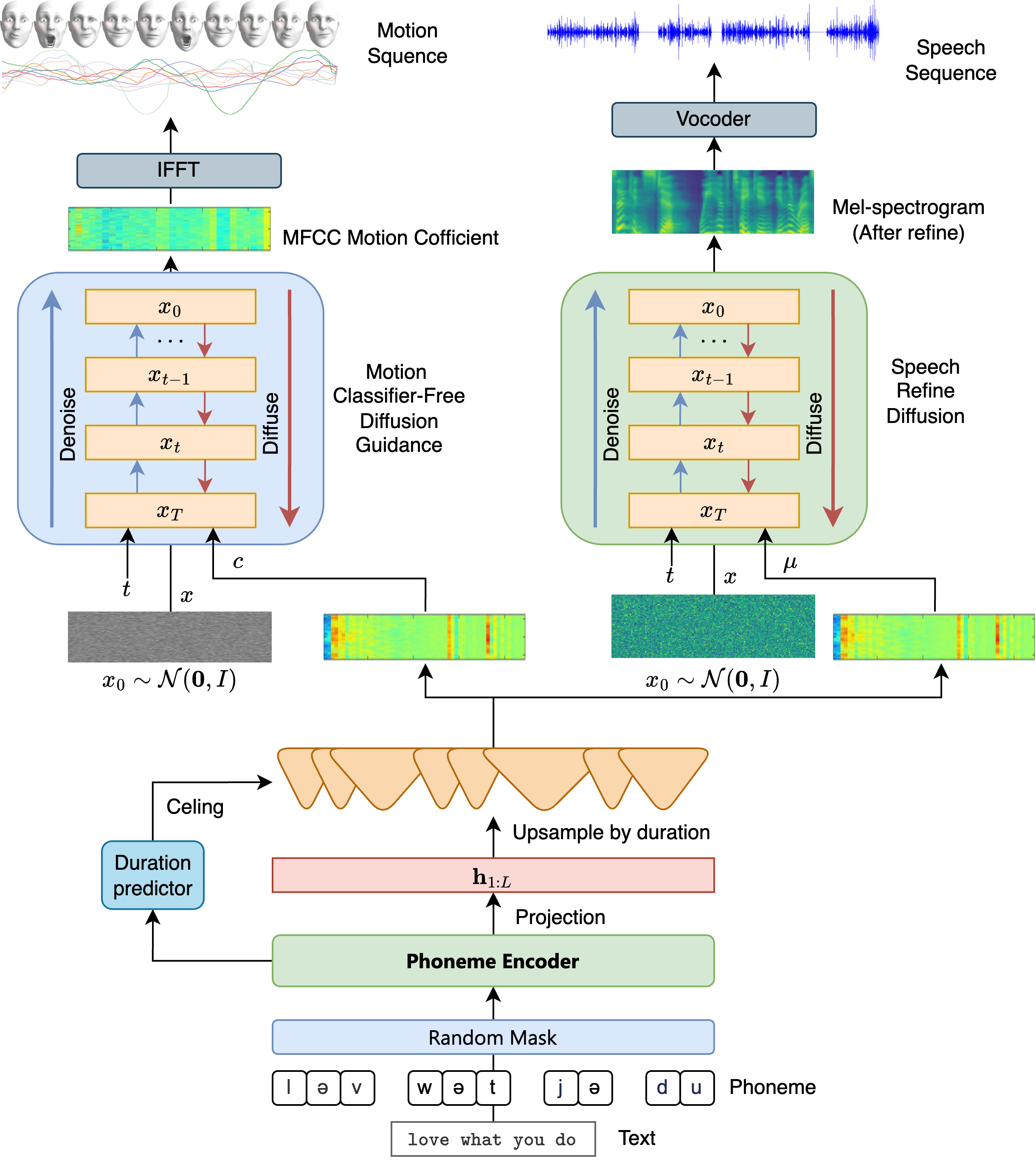
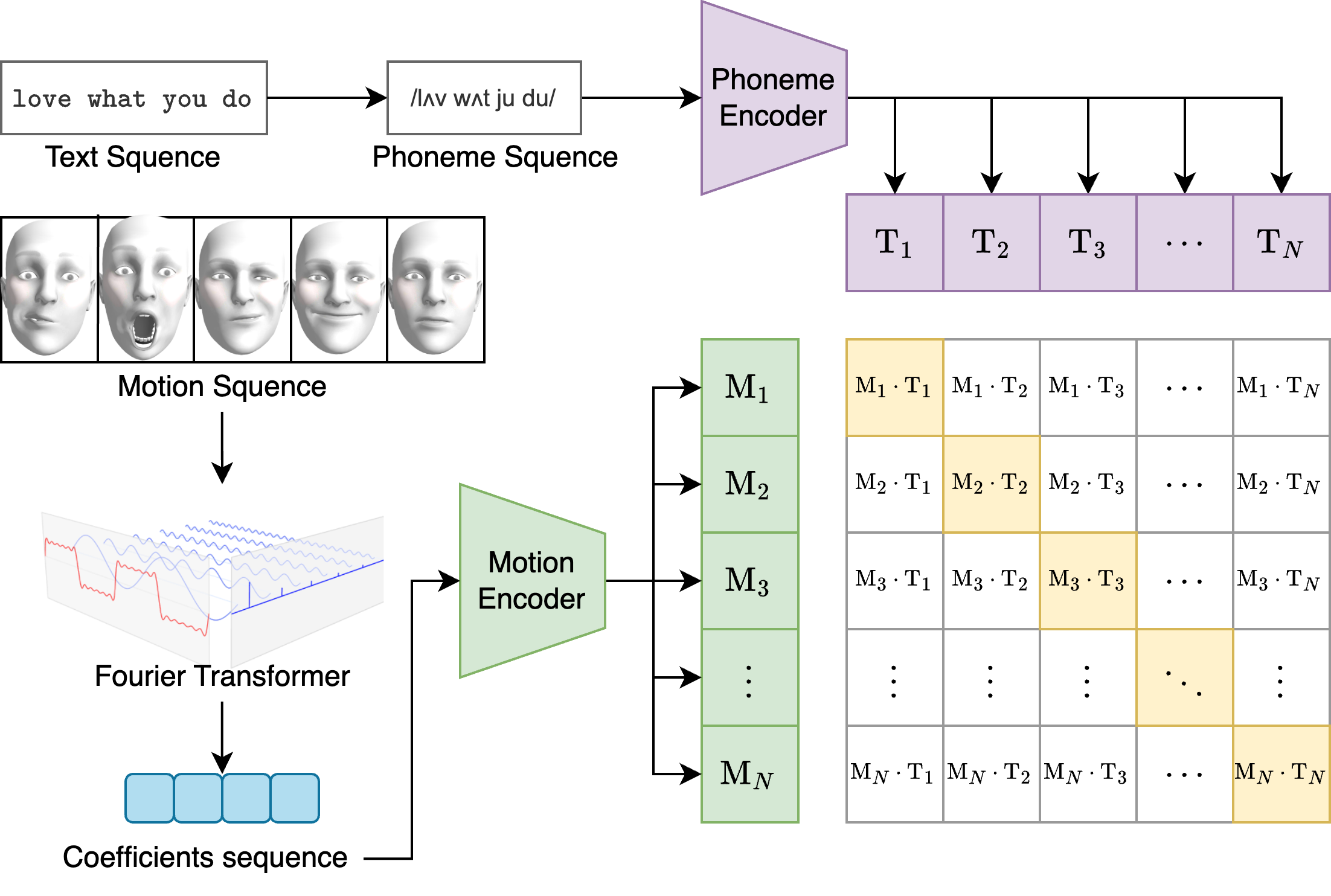
Automatic Speech Recognition (ASR) systems traditionally struggle with speaker variability, often requiring extensive data per user to achieve high accuracy. This paper introduces ParrotTranscribe, a novel ASR framework that learns personalized speech representations by directly aligning raw audio waveforms with their phonetic sequences in a self-supervised manner. At the core of ParrotTranscribe is a CLIP-inspired contrastive learning objective that maps masked segments of mel-spectrograms to their corresponding phonemes. Unlike conventional approaches, our method incorporates a speaker-specific reference embedding, inspired by F5-TTS, which conditions the model to adapt to unique vocal characteristics. This allows the system to learn that the same phoneme can have distinct acoustic representations across different speakers. The mel-spectrogram segments are encoded using a ConvNeXT-based encoder, and the resulting embeddings are used for both contrastive alignment and final phoneme prediction via a Connectionist Temporal Classification (CTC) decoder. We demonstrate that this pre-training paradigm effectively learns robust and personalized audio-phoneme mappings, serving as a powerful foundation for building accurate and adaptable end-to-end ASR systems, particularly in scenarios with limited labeled data or for personalized user applications.